AsyncChromiumLoader
웹 사이트에서 정보를 가져올 수 있는 방법은 두 가지가 있습니다.
첫 번째는 playwright와 chromium을 사용하는 것입니다. playwright는 borwser control(브라우저 컨트롤)을 할 수 있는 package입니다.
selenium이랑 비슷하다고 할 수 있습니다. 마찬가지로 browser를 control합니다. 이 도구는 많은 양의 javascript 코드가 있는 웹 사이트로부터 data를 추출할 때 사용합니다. 그런 웹 사이트는 접속 직후에는 모든 data를 바로 사용할 수 없습니다. 우리는 웹 사이트가 모든 api로부터 data를 load할 때 까지 조금 기다려야 합니다. 그리고 data를 읽고 사용할 수 있는 것이죠. 이 때문에 playwright와 chromium을 사용하게 됩니다. Langchain에서는 최신 LangChain Intergration으로 5줄의 코드면 다 할 수 있죠.
두 번째 방법은 우리가 직접 각 웹 사이트의 sitemap을 읽는 것입니다.
어떤 웹 사이트들은 sitemap을 갖고 있습니다. openai.com도 sitemap을 갖고 있는데요, 웹사이트의 sitemap을 확인하려면 url뒤에 /sitemap.xml을 입력해서 확인할 수 있습니다. 모든 url의 directory들을 확인할 수 있고 이는 openai 웹 사이트에 의해 만들어진 것들이죠.
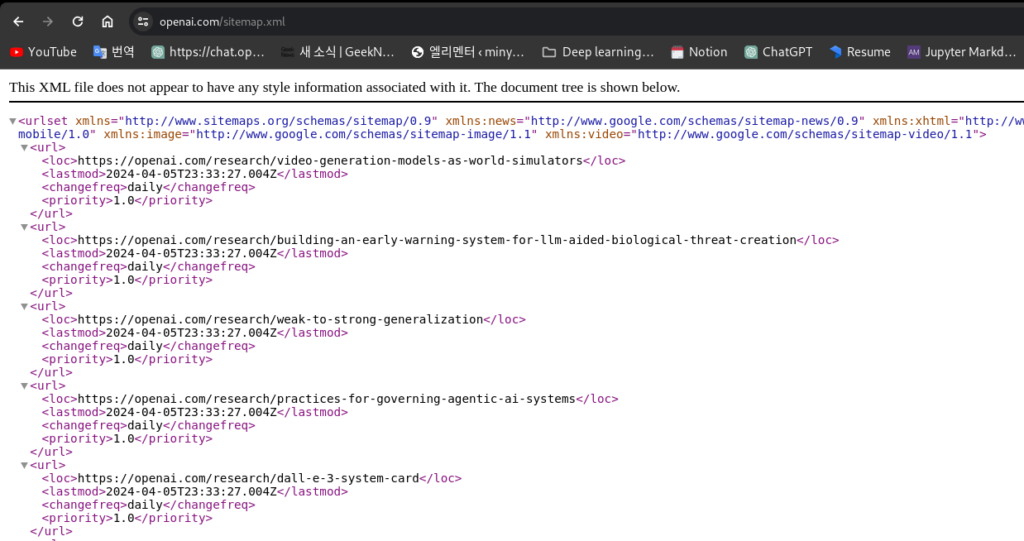
sitemap을 사용하면 웹 사이트에 존재하는 모든 page의 url들을 찾아낼 수 있습니다. 다시 정리해보면 웹 사이트의 데이터를 얻는 방법 중 playwright + chrominum이 필요한 경우는 대상 웹사이트에 sitemap이 없거나 javascript가 load 되는 것을 기다려야 하는 경우입니다. 아주 동적인(dynamic) 웹 사이트에서는 chromium과 playwright를 사용할 것입니다. 그리고 OpenAI 웹 사이트처럼 대부분이 text로 구성되어있고, 동적인 데이터가 거의 없는 곳에서는 즉, 대부분 정적인(static) text로 구성된 웹 사이트에서는 Sitemap loader를 사용할 것입니다. 두 가지 모두 LangChain Integration이 있어서 아주 쉽게 사용 가능합니다.
Streamlit을 사용해서 웹 사이트로 쉽게 우리의 SitemapGPT를 만들어볼건데요, 우선 실습중인 가상환경 내부에서 playwright를 설치해주셔야 합니다.
playwright install로 설치할 수 있지만, 가끔 안되는 경우가 있습니다.
그럴 때는 ‘pip install pytest-playwright’ 먼저 입력하고 ‘playwright install’ 진행했습니다.
설치가 완료되었다면 from langchain.document_loaders import AsyncChromiumLoader 코드를 통해 AsyncChromiumLoader를 사용해봅시다.st.sidebar 웹사이트의 사이드바에 우리가 지정한 url을 넣을 수 있도록 설정합니다.

AsyncChromiumLoader는 url의 list를 입력받습니다. 하지만 우리가 사용하려는 url은 하나 뿐입니다. 간단하게 리스트안에 url 변수를 넣어주면 해결 !
그리고 아래의 코드를 입력하면 웹사이트에서 잘 동작하는 것을 확인할 수 있습니다.
아무것도 해준게 없는데 잘 작동합니다.
여기 보이듯이 전체 웹사이트를 scarpe해왔습니다.
아주 많은 HTML을 얻을 수 있고, 여기 어딘가에서 우리가 원하는 부분의 text를 얻을 수 있을 것입니다. 현재는 HTML이 있는데, 저희는 Chatbot이 HTML을 그대로 읽기를 원하지 않죠? 이걸 다 읽기에는 비용도 많이들지만, HTML을 읽는 것은 아무 의미가 없기 때문입니다.

그래서 우리는 Transformer를 이용할 것입니다. 변환을 해주는 작업이 필요한 것이죠. 좋은 점은 LangChain은 당연하게 Transformer를 제공하기 때문에 편하게 사용할 수 있습니다.
from langchain.document_transformers import Html2TextTransformerhtml2text_transformer = Html2TextTransformer()이 Transformer는 이름 그대로 동작하게 됩니다. 이전의 코드에서 transformer를 적용시키고 결과를 확인해보면 순수 text가 된 것을 확인할 수 있습니다. HTML 태그가 모두 제거되었죠?
사용해본 것처럼 , AsyncChromiumLoader와 Transformer는 간단히 결합하여 사용할 수 있습니다. 특정 웹 사이트를 스크랩할 때 아주 유용합니다. 이게 바로 AsyncChrominumLoader의 멋진 기능이죠. 그런데 지금은 사용하지 않을 것입니다. 왜냐면 많은 URL을 가지고 사용하게 되면 상당히 느려지기 때문입니다. 왜냐하면 우리가 완전한 browser를 실행 중이기 때문인데요, 저 페이지를 스크랩하면서 이 모든 코드와 text를 얻었지만 그 과정에서 브라우저는 볼 수 없었습니다. 그건 playwright를 headless 모드로 실행했기 때문입니다.
headless가 의미하는 것은 우리의 browser process가 우리의 컴퓨터로부터 시작되었다는 것입니다. 그래서 많은 browser process를 실행하면 속도가 느려질 수 있습니다.
AsyncChromiumLoader의 속성에 들어가면 headless를 False로 설정할 수 있는데, 이렇게 설정하면 Chromedriver로 크롤링을 할 때 크롬창을 하나 띄우고 시작하는 것처럼 브라우저 창을 먼저 우리에게 보여주게 됩니다.


SitemapLoader
이제는 AsyncChromiumLoader와 Transformer 대신 다른 것을 사용할 것입니다.
from langchain.document_loaders import SitemapLoader로 SitemapLoader를 import 해줍니다. 이제 사용자가 URL을 입력했는지, 그리고 해당 URL에 XML sitemap이 포함되는지 확인하는 로직을 만들어봅시다. 만약 URL이 없다면 error를 보여주면서 어플리케이션의 충돌을 미리 방지합니다.
그리고 SitemapLoader에 우리가 가져온 URL을 넣어서 결과를 확인하는 코드도 추가해줄게요.
위의 코드를 실행시키면 시간이 좀 걸립니다. 왜냐하면 sitemap에 있는 모든 URL을 봐야하기 때문이죠. 우선 웹 사이트에서 데이터를 가져올 때는 스크랩을 너무 빠르게 하면 안된다는 것입니다. 사이트에서 차단당할 수도 있어요. 디폴트로는 1초 간격으로 스크랩할 수 있도록 설정할 수 있습니다.

웹사이트에서 결과를 확인해보면 606개의 결과를 받았네요. 여기서 주목해야할 점은 Sitemap Loader가 page text의 HTML 코드를 이미 정리했다는 것입니다.
또 text가 여전히 약간 지저분하다는 것이죠. 왜냐하면 우리는 말 그대로 모든 텍스트를 그대로 스크랩해와서 그렇습니다. 웹사이트의 메뉴 부분까지 텍스트로 구성된 모든 요소를 가져오는 것이죠. 그래서 저희가 해야하는 일은 우리에게 필요한 텍스트 데이터만 남기도록 정리해야할 필요가 있습니다. 예를 들어 header와 footer를 지워버리고 문서들을 split해서 읽기 편하게 만들 수 있습니다.


url을 받아서 웹사이트를 로드하는 함수를 만들어줬습니다. 함수의 내용은 위에서 작성한 코드와 동일합니다. @st.cache_data 는 load_website가 한 번 실행된 후 같은 url로 다시 호출된다면 아무 일도 하지않게 설정한 것입니다. 이렇게 설정하고 웹사이트에서 동일한 url로 실행시키면 fetch에 소요되는 시간이 아예 없이 바로 결과를 볼 수 있습니다.