Transformer의 탄생 배경

자연어 처리 분야에서 순환신경망(RNN)은 오랫동안 메인 모델로 사용되어 왔습니다. 하지만 RNN은 길이가 길어질수록 성능이 저하되는 단점이 있었습니다. 그래서 어텐션(Attention) 메커니즘을 통해 입력과 출력 사이의 의존성을 직접적으로 모델링할 수 있는 트랜스포머가 제안되었습니다.
기존 순차 모델들이 단어 하나하나를 차례로 처리했던 것과 달리, 트랜스포머는 어텐션을 통해 전체 문장을 한번에 참조할 수 있게 되었습니다. 이를 통해 병렬 처리가 가능해져 계산 효율이 크게 향상되었습니다. 또한 문장의 길이에 상관없이 성능이 유지되는 장점도 가지고 있습니다.
이렇게 혁신적인 아이디어를 제시한 ‘Attention is all you need’ 논문은 트랜스포머 모델의 기반이 되었습니다. 이 논문이 발표된 이후 자연어 처리뿐 아니라 컴퓨터 비전, 음성 인식 등 다양한 분야에서 어텐션 기반 모델이 엄청난 주목을 받게 되었죠!
예를 들어 ‘저는 학생 입니다’라는 문장이 주어졌을 때 이를 영어로 바꾸면 ‘I’m student’죠?
이러한 예시를 가지고 처음부터 끝까지 끌고 가볼게요.
우선 각 단어들을 원 핫 인코딩하여 숫자로 변환하고 이를 각각 x1 x2 x3 라고 해봅시다.
여기서 x1 x2 x3를 하나씩 넣을거예요. 한꺼번에 넣지 않고 한번에 넣으면 RNN이고 한꺼번에 넣으면 트랜스포머 이런식으로 생각해주시면 됩니다.
Seq2Seq
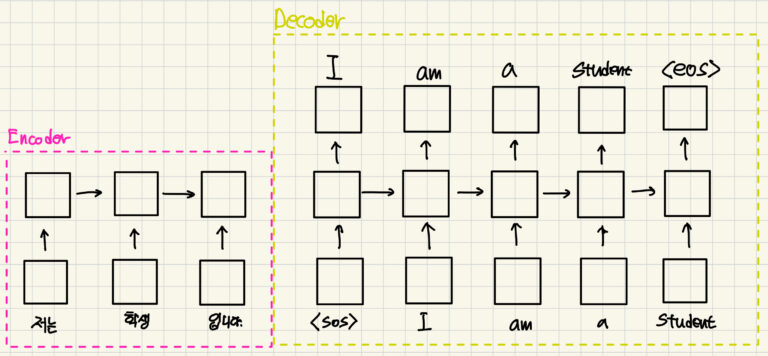
Seq2Seq 구조는 입력에서 출력으로의 변환 과정에서 각 입력 단어가 이어지는 출력 단어를 예측하도록 설계되었습니다.
이 과정은 ‘시작 토큰(SOS)’로 시작하여 첫 번째 단어 ‘I’, 그 다음 ‘am’과 같이 순차적으로 단어를 예측하고, ‘종료 토큰(EOS)’에 도달할 때까지 계속됩니다. 이러한 방식은 지도학습 방법에 속합니다. 왜냐하면 입력으로 정답값이 들어가기 때문이죠.
하지만, Seq2Seq 모델에는 몇 가지 문제점이 존재합니다. 특히, ‘멀수록 잊혀진다’는 문제가 있으며, 이는 인코더(Encoder)와 디코더 (Decoder)모두에서 발생합니다.
이 문제는 문장의 뒷부분에 위치한 단어의 정보가 상대적으로 더 강하게 context vector에 반영되는 경향이 있습니다.
따라서 문장의 처음에 위치한 단어의 정보는 상대적으로 흐려지는 현상이 발생합니다. 예를 들어, 문장에서 ‘I’, ‘am’, ‘a’를 출력할 때마다, 디코더는 context vector에서 ‘입니다’를 가장 열심히 보게됩니다. 왜 일까요? ‘입니다’가 context vector이기 때문이죠.
다른 단어들의 정보는 상대적으로 덜 중요하게 처리합니다. 이러한 문제는 context vector가 문장의 마지막 단어에 가장 큰 영향을 받기 때문에 발생합니다.
RNN summary
- 마지막 단어를 가장 중요하게 보니까 ! 이건 인간의 사고 방식이 아니다 !
- -LSTM, GRU가 나왔지만 근본적인 문제(멀수록 잊혀진다)를 해결할 수 없었다.
- Attention은 Transformer 논문 이전부터 존재했던 개념.
- RNN -> RNN + attention -> Transformer로 발전
RNN + attention
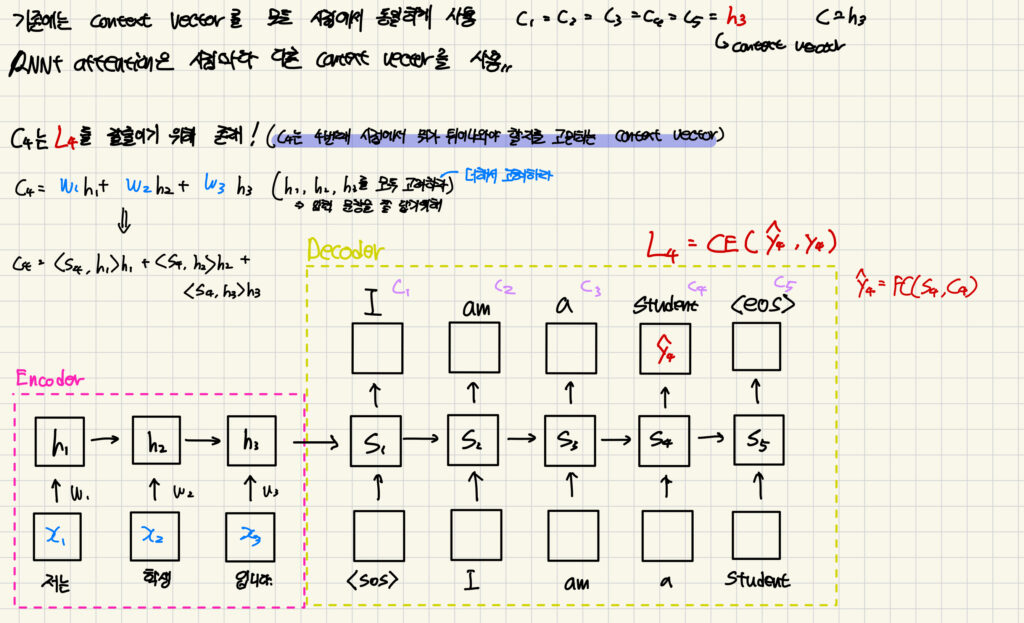
기존에는 h3(context vector)가 RNN의 구조적 특성 때문에 입력 문장인 ‘나는 학생 입니다.’를 잘 담았다고 생각했습니다. 근데 RNN + Attention의 입장에서는 그게 충분하지 않다고 생각을 한 것입니다.
그래서 ‘이제부터 h1, h2, h3가 각 단어를 잘 담았다고 해보자!’ 라고 제안합니다.
‘저는’에 해당하는 x1을 h3가 잘 담지 못하고 있죠? 그렇기 때문에 그냥 h1이 x1을 제대로 담당하고, h2가 x2를 제대로 담당하고, h3가 x3를 제대로 담당하는 녀석으로 보고 그 세 개를 더해서 context vector를 만들어보자는 것입니다.
그런데 이렇게만 하면 좀 아쉽습니다.
C4는 h1~h3 중에서 어떤 녀석이 가장 중요하게 고려되어야 할까요 ?
영어로 ‘student’니까 h2에 해당하는 ‘학생’ 이겠죠?
그래서 그냥 더해주는게 아니라 weighted sum을 합니다. 그리고 weight를 업데이트 해주는 것이죠. 어떤 단어를 주목할지(가중치를 더 부여할지) 학습하는 것입니다. 그런데 아직 부족합니다. 이렇게만 하면 문제가 있어요.
위의 예시를 그대로 사용한다면 \( C_4=W_1h_1+W_2h_2+W_3h_3 \) 식에서 W2 를 더 키워주려고 하겠죠?
식에서 를 더 키워주려고 하겠죠?
잘 생각해보면 2번째 라는 시점이 중요한게 아니라 ‘학생’이라는 단어 자체가 중요합니다.
그런데 위의 식으로 계산하면 시점에만 가중치가 붙을 거 같아요. 왜냐하면 라는 존재만 학습하기 때문이죠. 이렇게 하면 나중에 문장의 구조가 바뀌어서 ‘저는 딥러닝을 공부하는 학생입니다.’ 이런 문장이 나올 경우 ‘학생’이라는 단어를 잘 못찾아갈 가능성이 있습니다.
그래서 W(가중치)에 단어를 반영할 수 있도록 해보자는 것입니다.
어떻게 해보면 좋을까요?
‘현재 단어도 보자 !’입니다. C_4 (4번째 시점)에서의 단어는 ‘an’입니다. 이 ‘an’에서 어떤 단어를 주목하면 좋을지 x1 , x2 , x3 를 보자는 것이예요.
현재 ‘an’을 담고있는 것은 S4 입니다. ‘저는 학생 입니다’를 담고있는 x1, x2,x3 이 벡터들의 관계를 S4의 입장으로 한 번 살펴보자는 것입니다. 이 벡터들은 시점이 아니라 입력 문장이 가지고 있는 단어를 담고있어서 시점에 따라 다른 값이 아닙니다. 그래서 그 단어 그대로 weighting을 해줄 수 있다는 것입니다.
정리하자면, ‘I am an’까지 본 상황에서는 입력 문장을 봤을 때 어떤 단어를 중요하게 봐야할지를 weight로 나타낸게 바로 Attention인 것이고 이걸 내적으로 나타냅니다.
내적(dot product)은 벡터간에 닮음의 정도를 나타냅니다.
내적을 사용한 식은 이렇게 됩니다.
\( C_4 = <S_4,h_1>h_1 + <S_4,h_2>h_2 + <S_4,h_3>h_3 \)
이렇게 C4 를 만들고 이걸 S4와 엮어서 Cross Entropy 통과시키죠. ( L4=CE(hat{y_4},y_4 )
그렇게 함으로써 L_4 를 줄이기 위해서 Weight들이 잘 학습이 되겠죠?
다시보면 기존의 방법은 이 weight들이 ‘an’과 거리가 너무 멀어서 흐려지는 문제가 발생한다고 했는데, 이렇게 하면 그 거리 문제를 확실히 해결할 수 있어보이네요.
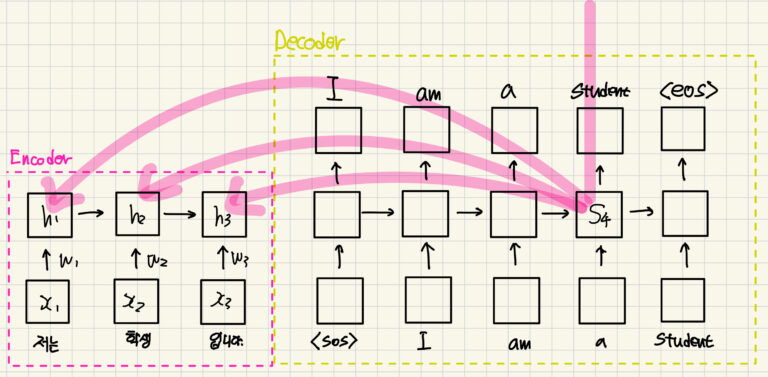
아래의 그림을 보면 어떻게 계산이 되는지 눈으로 확인할 수 있습니다. 그림을 보면 \( C_4 \)에서 모든 루트를 거치지 않고 바로 순간이동 해 버립니다.
그러면 멀수록 흐려진다는 문제(gradient가 매우 작아짐!)가 해결되면서 Gradient가 풍부해집니다.
RNN + Attention Summary
- Decoder가 마지막 단어만 열심히 보는 문제(갈수록 흐려진다) <- attention으로 해결
- RNN의 Vanishing Gradient(멀수록 잊혀진다) <- self-attention으로 해결
- 흐려지는 정보에 attention <- self-attention 으로 해결 !
Self-Attention
self-attention에 대해서 알아봅시다. 수식은 아래와 같습니다.
\(h_2 = <h_2 ,h_1>h_1 + <h_2, h_2>h_2 + <h_2,h_3>h_3\)
self-attention은 \(h\)끼리 내적을 해보는 거예요. $h_1$ $h_2$ $h_3$ 끼리의 내적을 통해서 관계를 살펴보자는 것이죠. 이렇게 하면 어떤 단어끼리 연관이 있는지 어떤 벡터가 더 가까운지를 알아볼 수 있습니다. 그리고 어떤 단어가 서로 가까워야 하는지를 학습시킬 수 있습니다. 그걸 어떻게 알죠?
h에는 이미 weight가 있기 때문에 업데이트를 할 수 있는 것입니다.
예를 들어서, \(h_2\) 는 ‘학생’이라는 단어를 잘 담기 위해서 주변에 어떤 단어를 봐야할지 보는거예요. 내적을 통해서 어떤 단어랑 내적했을 때 가장 loss가 적은지 알아서 알아낸다는 것입니다.
뭐로? Gradient Descent로 !
이런 구조라면 앞서 RNN+Attention의 한계에서 언급했던 “쓰다”와 “글을”이 잘 붙도록 학습이 됩니다. 그러도록 메트릭스가 학습되기 때문이죠.
그래서 이걸 self-attention이라고 합니다. 왜 self가 붙냐면 입력 문장안에서 attention을 하기 때문이에요. 간단합니다.
드디어 Transformer
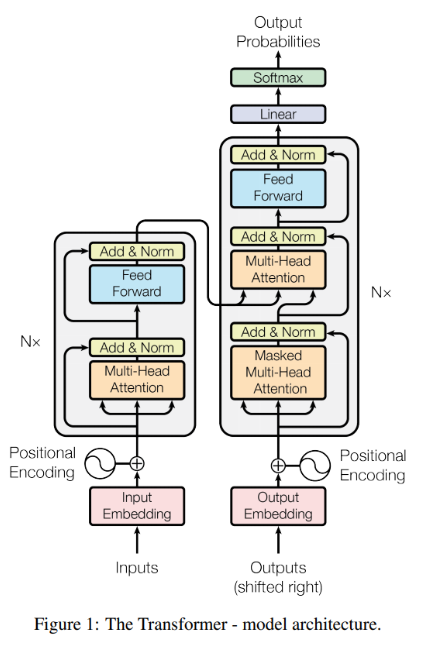
Transformer의 구조를 나눠서 각 구조의 역할과 특징에 대해 알아봅시다.
Input 부분을 먼저 볼게요. Transformer는 NLP task를 처리하는 모델로 나오고 들어가는 데이터는 텍스트 데이터로 구성됩니다. 데이터의 구조는 [문장, 단어의 수, 차원]으로 이루어져있습니다.
예를 들어, 32x50x512는 32개의 문장인데 50개의 단어로 이루어져있고 각 단어는 512차원이다! 이렇게 해석할 수 있겠죠?
또 이런 질문이 있을 수 있습니다. 입력으로 들어오는 문장들은 모두 길이가 다를 텐데 어떻게 하나의 tensor에 다 담을 수 있죠?
- 이때 pad 토큰을 사용합니다. pad 토큰도 one-hot 되어 있기 때문에 하나의 단어 역할을 하게됩니다. 아래의 그림을 참고해주시면 됩니다 !

처음에 입력값으로 들어가게되는 Inputs는 32x50x7851 이런 식으로 one-hot 되어 있습니다.
즉, ‘저는’=1,0,0 ‘학생’=0,1,0 ‘입니다.’=0,0,1 이게 아니고
저는 = 0,……1,0,0….. (1482 번째에 1 나머지 0)
학생 = 0,…..1,0,0…… (5821 번째에 1 나머지 0)
입니다 = 0,0,…..1,…. (243 번째에 1 나머지 0) 이런 식으로 되어있다는 뜻입니다.
따라서 7851 이라는 숫자는 내가 사용할 수 있는 한글 단어의 총 개수입니다. 그래서 그 중에서 1인 값은 7851개의 단어 중 한 ‘단어’로 생각하면 됩니다.
실제 구현에서는 32×50으로 1482과 같은 인덱스만 적혀있습니다. 32x50x7851을 nn.Linear(7851,512) 통과시키면 그게 단어 임베딩 벡터가 되는 것입니다. (32x50x512)
(실제 구현에서는 nn.Embedding을 사용합니다.)
원 핫 인코딩은 결국 행뽑기다 !
아래의 그림을 보면 7851의 길이를 가진 벡터중 4번째 벡터만 1이고 나머지는 모두 0입니다.
그 상태에서 7851×512와 곱해주면 어떻게 되죠? 1에 해당하는 4번째 weight만 뽑아져 나오겠죠. 이게 단어 임베딩 벡터가 되겠습니다.

Positional Encoding
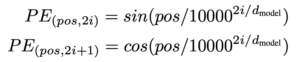
RNN이나 LSTM과는 다르게 트랜스포머는 입력 순서가 단어 순서에 대한 정보를 보장하지는 않습니다. 트랜스포머의 경우 시퀀스가 한 번에 병렬로 입력되기 때문에 단어 순서에 대한 정보가 사라집니다. 따라서 단어 위치를 식별할 수 있도록 위치에 대한 정보를 별도로 넣어줘야 합니다. 논문에서는 positional encoding으로 이 문제를 해결합니다.
위치에 따라서 어떤 벡터를 더해줄지 AI가 알아내도록 합니다.
그런데 논문에서는 이걸 따로 학습시키지는 않고 고정된 벡터를 사용합니다.
sine & cosine 함수를 사용해서 positional encoding 벡터를 만드는데요.
이 함수는 -1~1 사이를 반복하는 주기함수입니다. 즉 1을 초과하지 않고 -1 미만으로 떨어지지 않으므로 값이 너무 커지지 않도록 합니다.
(여기서 pos는 단어 위치, i는 0..255)
sin값과 cos값이 번갈아 나오는 특이한 형태입니다. 간단히 말하자면 아래의 그림에서 0번째 가로줄을 0번째 단어의 임베딩 벡터에, 1번째 가로줄을 1번째 단어의 임베딩 벡터에 더해주는 것이죠.
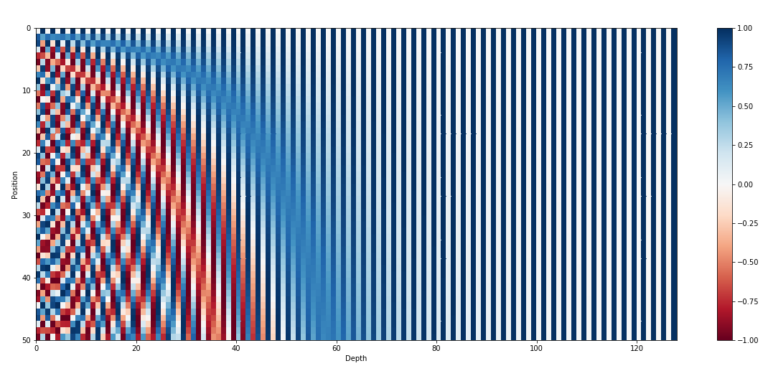
Transformer가 학습하는 layer
입력 문장 내에서 단어 간의 관계를 학습시키기 위해 ‘내적’을 사용한다고 했습니다.
\( h_2 = <h_2 ,h_1>h_1 + <h_2, h_2>h_2 + <h_2,h_3>h_3 \)
그런데 내적을 통해서 어떤 단어에 주목해야 할지를 AI가 찾아내도록 할 수 있을까요?
내적은 그냥 곱해서 더하는 것 뿐인데? 내적은 파라미터가 필요한 연산이 아니란거죠.
그러면 어떤게 학습 파라미터인지 생각해봐야 합니다. 내적할 단어 임베딩 벡터를 선형 변환하는 Fully connected layer를 앞에 놓고 얘를 학습시켜야합니다.
FC layer가 뭐죠? 그냥 weight matrix 곱하고 bias 더하는거죠.
matrix(행렬)을 곱한다는 말은 ‘선형변환’과 같은 말이죠?
그래서 이 ‘선형변환’이 학습된다는 것입니다. 어떻게 선형변환을 할까! 라는 것이죠.
첫번째 단계에서 만든 32x50x512를
fc_q = nn.Linear(512,64)
fc_k = nn.Linear(512,64)
fc_v = nn.Linear(512,64)
모두에 통과시켜서 Q,K,V를 얻습니다.
단어 임베딩 벡터에 위치 임베딩 벡터를 더한 상태에서 nn.Linear를 병렬적으로 세 번을 통과시키는 것입니다.
예시의 편의를 위해서 1x3x512로 하도록 하겠습니다.
‘나는 학생 입니다’ 문장을 예로 들어서 아래의 그림을 보면 Q,K,V가 각각 나왔습니다.
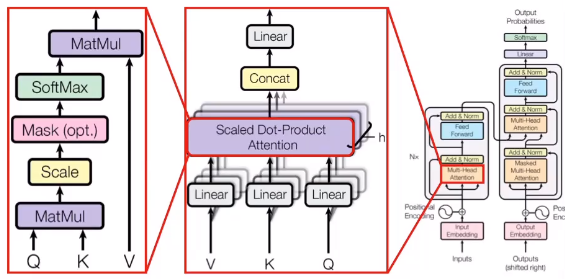
3×64 짜리가 3개가 탄생하게 되는 것이죠. Query, Key, Value라는 매우 중요한 녀석들이 등장합니다. 데이터베이스에서 자주 나오는 개념이죠?
Query는 관계를 물어볼 기준 단어 벡터이고,
Key는 Query와 관계를 알아볼 단어 벡터이고,
Value는 관계를 알아볼 단어의 의미를 담은 벡터입니다.
왜 Q,K,V를 병렬적으로 학습할까요? 제 생각에는 각 벡터마다 기능을 특화해주려고 그런 것 같아요. Query의 역할은 관계를 물어봐야하니까 ‘질문을 잘하는’ 벡터로 만들어주고, Key의 역할은 Query와 관계를 잘 알아봐야 하니까 ‘답변을 잘하는’ 벡터가 되는 것이고, Value는 관계를 알아볼 단어의 의미를 담은 벡터이므로 ‘표현을 잘하는’ 벡터로 만들어버리자! 이렇게 이해하고 있습니다. (Vision에서는 Depth-wise와 비슷하다고 생각이 드네요)
attention 수식을 보면 루트 dk로 나눠주는데, 이걸 나누는 이유는 dk가 클수록 내적의 분산이 자꾸 커져서 루트 dk로 나눠 줌으로써 softmax 미분이 작아지는 것을 방지하기 때문입니다.
그래서 전체적인 입력 문장이 들어와서 Q,K,V의 attention 계산 과정은 아래와 같습니다.

마지막 결과에서 두 번째 행이 바로 \(h_2 = <h_2 ,h_1>h_1 + <h_2, h_2>h_2 + <h_2,h_3>h_3\) 이 녀석이 되는거죠. 그래서 마지막 행렬은 저렇게 h1 h2 h3 얘네들을 담아놓은 행렬이 되는 것입니다.
한꺼번에 확 계산해버리는거죠. 행렬로 계산하면 도입할 수 있는 알고리즘이 많고 연산량 줄이는 방법이 많기 때문에 (병렬처리) 행렬을 사용하는게 정말 큰 장점이라고 할 수 있습니다.
아래의 그림을 보면 h라고 적혀있고, 뒤로 잔상이 보입니다.
위에서 봤던 그림이 `fc_q2=nn.Linear(512,64)` , `fc_k2=nn.Linear(512,64)` , `fc_v2=nn.Linear(512,64)` 이걸 해준거죠? 그래서 마지막 행렬 1개가 나왔습니다.
이 과정을 총 8번씩 해주는거예요
예를 들어 `fc_q2=nn.Linear(512,64)` , `fc_q2=nn.Linear(512,64)` `fc_q3=nn.Linear(512,64)` … `fc_q8=nn.Linear(512,64)` 이렇게 말이죠. (Q,K,V) 모두 동일하게.
h가 8개인걸 우리는 Multi-Head Attention(멀티 헤드 어텐션)이라고 부르기로 합니다.
헤드가 여러개라고 해서 멀티 헤드 어텐션이라고 하는거죠!
그렇다면 MHA(Multi-Head Attention)을 사용해서 얻는 효과는 무엇일까요?
이 논문의 가장 큰 contribution은 Attention도 아니고 Transformer도 아니고 MHA입니다. MHA는 이 논문 이전에는 없던 개념이거든요. 그래서 MHA에 대해서 잘 알고 계시는게 정말 중요하다고 생각합니다.
우선 1x3x64짜리 여덟개를 가로로 concat해서 1x3x512를 얻습니다.
그 후에 `nn.Linear(512,512)`를 통과하고 도로 1x3x512로 만들어줍니다.
들어온 입력과 같은 사이즈가 되는 것이죠.
원탁을 생각해봅시다. 원탁에 8명이 둘러앉아서 각자의 의견을 피력합니다.
2번째 행을 보고 ‘학생’에 대해서 각자 떠드는거예요. 그래서 헤드 각각 64개의 weight도 있고 서로의 의견을 취합해서 아래의 그림처럼 `nn.Linear(512,512)`를 통과시키는거죠.
오늘 준비한 내용은 여기까지 입니다. 다음 포스팅에서는 트랜스포머 구조의 나머지 부분을 포스팅하도록 하겠습니다.
Transformer 시리즈는 Transformer구조를 이용한 많은 모델들에 대한 논문을 최대한 리뷰해보도록 하겠습니다 🙂